

En Resumen
- Una nueva técnica llamada Multiplicación de Complejidad Lineal (L-Mul) podría reducir el consumo de energía de los modelos de IA hasta en un 95% sin comprometer la calidad.
- Investigadores de BitEnergy AI, Inc. han desarrollado L-Mul, que reemplaza las multiplicaciones intensivas en energía de punto flotante con simples adiciones de enteros en cálculos de IA.
- L-Mul aproxima las operaciones de punto flotante utilizando sumas enteras, lo que hace que los cálculos sean más rápidos y utilicen menos energía, manteniendo la precisión.
Una nueva técnica podría poner a las modelos de IA en una estricta dieta energética, reduciendo potencialmente el consumo de energía hasta en un 95% sin comprometer la calidad.
Investigadores de BitEnergy AI, Inc. han desarrollado Multiplicación de Complejidad Lineal (L-Mul), un método que reemplaza las multiplicaciones intensivas en energía de punto flotante con simples adiciones de enteros en cálculos de IA.
Para aquellos que no estén familiarizados con el término, el "floating-point" o "punto flotante" es una abreviatura matemática que permite a las computadoras manejar números muy grandes y muy pequeños de manera eficiente ajustando la posición del punto decimal. Puedes pensar en ello como una notación científica, pero en binario. Son esenciales para muchos cálculos en modelos de IA, pero requieren mucha energía y potencia de cómputo. Cuanto mayor sea el número, mejor será el modelo, y más potencia de cómputo requerirá. Fp32 es generalmente un modelo de precisión completa, con desarrolladores reduciendo la precisión a fp16, fp8 e incluso fp4, para que sus modelos puedan ejecutarse en hardware local.

El apetito voraz de la inteligencia artificial por la electricidad se ha convertido en una preocupación creciente. Por ejemplo, ChatGPT solo consume 564 MWh diariamente— suficiente para abastecer 18.000 hogares estadounidenses. Se espera que la industria de la inteligencia artificial en su conjunto consuma 85-134 TWh anualmente para 2027, aproximadamente la misma cantidad que las operaciones de minería de Bitcoin, según estimaciones compartidas por el Centro de Finanzas Alternativas de Cambridge.
L-Mul aborda el problema de energía de la IA de frente al reimaginar cómo los modelos de IA manejan cálculos. En lugar de multiplicaciones complejas de punto flotante, L-Mul aproxima estas operaciones utilizando sumas enteras. Entonces, por ejemplo, en lugar de multiplicar 123.45 por 67.89, L-Mul lo descompone en pasos más pequeños y fáciles usando la suma. Esto hace que los cálculos sean más rápidos y utilicen menos energía, manteniendo la precisión.
Los resultados parecen prometedores. “Aplicar la operación L-Mul en hardware de procesamiento de tensores puede potencialmente reducir un 95% el costo energético de las multiplicaciones de tensores de punto flotante por elemento y un 80% el costo energético de los productos punto,” afirman los investigadores. Sin complicarse demasiado, lo que eso significa simplemente es esto: si un modelo utilizara esta técnica, requeriría un 95% menos de energía para pensar y un 80% menos de energía para generar nuevas ideas, según esta investigación.
El impacto del algoritmo va más allá del ahorro de energía. L-Mul supera los estándares actuales de 8 bits en algunos casos, logrando una mayor precisión mientras utiliza significativamente menos cálculos a nivel de bits. Las pruebas en procesamiento de lenguaje natural, tareas de visión y razonamiento simbólico mostraron una caída promedio de rendimiento de solo el 0.07%—un intercambio insignificante por el potencial ahorro de energía.
Los modelos basados en transformadores, la columna vertebral de los grandes modelos de lenguaje como GPT, podrían beneficiarse enormemente de L-Mul. El algoritmo se integra perfectamente en el mecanismo de atención, una parte computacionalmente intensiva de estos modelos. Las pruebas en modelos populares como Llama, Mistral y Gemma incluso revelaron cierta ganancia de precisión en ciertas tareas de visión.
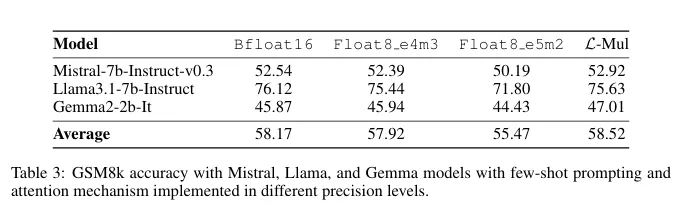
En un nivel operativo, las ventajas de L-Mul se vuelven aún más claras. La investigación muestra que la multiplicación de dos números float8 (la forma en que operarían los modelos de IA hoy en día) requiere 325 operaciones, mientras que L-Mul utiliza solo 157, menos de la mitad. “Para resumir el análisis de error y complejidad, L-Mul es tanto más eficiente como más preciso que la multiplicación fp8,” concluye el estudio.
Pero nada es perfecto y esta técnica tiene un gran talón de Aquiles: Requiere un tipo especial de hardware, por lo que el hardware actual no está optimizado para aprovecharlo al máximo.
Es posible que ya estén en marcha planes para hardware especializado que admita nativamente cálculos L-Mul. “Para desbloquear todo el potencial de nuestro método propuesto, implementaremos los algoritmos de kernel L-Mul y L-Matmul a nivel de hardware y desarrollaremos APIs de programación para el diseño de modelos de alto nivel,” afirmaron los investigadores. Esto podría llevar potencialmente a una nueva generación de modelos de IA que sean rápidos, precisos y súper económicos, haciendo que la IA energéticamente eficiente sea una posibilidad real.